[ python ] Pandas 라이브러리 불러오기 사용하기
본문
#Pandas 라이브러리 불러오기, 사용하기
import pandas as pd
#serise 사용
population=pd.Series([9904312,3448737,289045,2466052])
population
0 9904312
1 3448737
2 289045
3 2466052
dtype: int64
population = pd.Series([9904312,3448737,289045,2466052],
index=['서울','부산','인천','대구'])
population
서울 9904312
부산 3448737
인천 289045
대구 2466052
dtype: int64
#series에서 실제 데이터 값만 추출하기 -> .values
population.values
array([9904312, 3448737, 289045, 2466052], dtype=int64)
#Series에서 index 내용만 추출하기 -> .index
population.index
Index(['서울', '부산', '인천', '대구'], dtype='object')
population.dtype
dtype('int64')
#Series에서 이름 지정하기
#전체적인 Series에 이름 지정 -> .name
#index에 대하여 이름 지정-> .index.name
population.name="지역별 인구수"
population.index.name="도시"
population
도시
서울 9904312
부산 3448737
인천 289045
대구 2466052
Name: 지역별 인구수, dtype: int64
#Series 의 연산
population*10
도시
서울 99043120
부산 34487370
인천 2890450
대구 24660520
Name: 지역별 인구수, dtype: int64
#Series 인덱싱 구하기
print(population[1])
print(population['부산'])
3448737
3448737
#[서울 대구 부산]
print(population[[0,3,1]])
print(population[['서울','대구','부산']])
도시
서울 9904312
대구 2466052
부산 3448737
Name: 지역별 인구수, dtype: int64
도시
서울 9904312
대구 2466052
부산 3448737
Name: 지역별 인구수, dtype: int64
population>=2500000
도시
서울 True
부산 True
인천 False
대구 False
Name: 지역별 인구수, dtype: bool
population[population>=2500000]
도시
서울 9904312
부산 3448737
Name: 지역별 인구수, dtype: int64
population[(population>=2500000) & (population<=5000000)]
도시
부산 3448737
Name: 지역별 인구수, dtype: int64
population
도시
서울 9904312
부산 3448737
인천 289045
대구 2466052
Name: 지역별 인구수, dtype: int64
#시작점부터 끝점의 -1만큰 가져온다.
population[1:3]
도시
부산 3448737
인천 289045
Name: 지역별 인구수, dtype: int64
#명칭으로 입력시 해당이름을 포함해서 가져온다.
population['서울':'인천']
도시
서울 9904312
부산 3448737
인천 289045
Name: 지역별 인구수, dtype: int64
#Series를 생성할 수 있는 2번째 방법
data = {'서울':9631482, '부산':3393191, '인천':2632035, '대전':1490158}
data
{'서울': 9631482, '부산': 3393191, '인천': 2632035, '대전': 1490158}
population2=pd.Series(data)
population2
서울 9631482
부산 3393191
인천 2632035
대전 1490158
dtype: int64
population3=pd.Series({'서울':9631482, '부산':3393191, '인천':2632035, '대전':1490158})
population3
서울 9631482
부산 3393191
인천 2632035
대전 1490158
dtype: int64
#isnull() -> null값을 찾아 True로 표현
ds.isnull()
#Series 데이터 갱신, 추가 삭제
population['부산']=2500000
population
도시
서울 9904312
부산 2500000
인천 289045
대구 2466052
Name: 지역별 인구수, dtype: int64
#Series 데이터 추가
population['대전'] = 1700000
population
도시
서울 9904312
부산 2500000
인천 289045
대구 2466052
대전 1700000
Name: 지역별 인구수, dtype: int64
del population['인천']
population
도시
서울 9904312
부산 2500000
대구 2466052
대전 1700000
Name: 지역별 인구수, dtype: int64
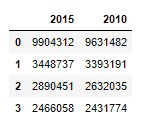
#1) How to create a DataFrame
data = {"2015":[9904312,3448737,2890451,2466058],
"2010":[9631482,3393191,2632035,2431774]}
df=pd.DataFrame(data)
df
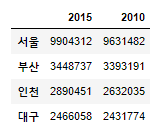
#Index a DataFrame
df.index=['서울','부산','인천','대구']
df
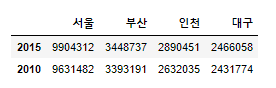
#2) How to create a DataFrame
data2 = [[9904312,3448737,2890451,2466058],
[9631482,3393191,2632035,2431774]]
ind=['2015','2010']
col=['서울','부산','인천','대구']
#pd.DataFrame( data, index=Index name, columns = column name)
df2=pd.DataFrame(data2, index=ind, columns=col)
df2
#Location the data
df2.T
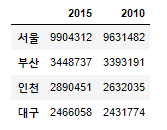
#Location the data
df2.T
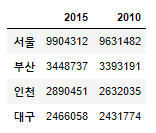
#Location the Save data
df3=df2.T
df3
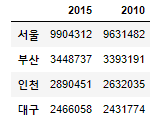
#DataFrame -> values, index, columns
print(df.values)
print(df.index)
print(df.columns)
[[9904312 9631482] [3448737 3393191] [2890451 2632035] [2466058 2431774]] Index(['서울', '부산', '인천', '대구'], dtype='object') Index(['2015', '2010'], dtype='object')
#DataFrame Indxing
df[['2015']]

#2010을 먼저 보여주고 2015를 뒤에 보여주기 위해서 index값을 차례로 적어준다
df[['2010','2015']]
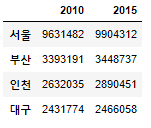
#DataFrame 값 추가하기
#2005년 컬럼명으로 인구수 대입
df['2005']=[9762546,3512547,2517680,2456016]
df
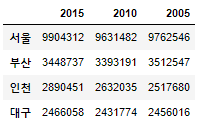
#서울 부산 인덱싱
df['서울':'부산']
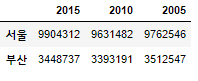
#0~1 인덱싱
df[0:2]
#loc[], iloc[]
#loc[] - 실제 인덱스를 사용하여 행을 가지고 올 때 사용하는 ->df.loc[행,열]
#loc['서울'] 등의 형태로 조회
#iloc[] - numpy의 array 인덱싱 -> df.iloc[]
#iloc[0,1] 등의 형태로 조회
df.loc['서울':'부산', '2015':'2010']
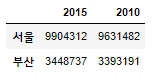
df.iloc[[2],[0]]

df.loc[['서울','인천']]
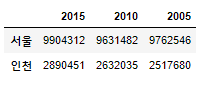
df.loc[['서울','인천'],['2015']]

df.loc[['서울', '인천'], ['2010','2005']]
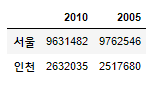
df.iloc[[0,2],[0,1]]
댓글목록 0
등록된 댓글이 없습니다.